Web-based UI for Stable Diffusion
Web-based UI for Stable Diffusion
Created by sd-webui
Visit sd-webui’s Discord Server 
Installation instructions for:
Want to ask a question or request a feature?
Come to our Discord Server or use Discussions.
Documentation
Want to contribute?
Check the Contribution Guide
sd-webui is:



Project Features:
- Two great Web UI’s to choose from: Streamlit or Gradio
- No more manually typing parameters, now all you have to do is write your prompt and adjust sliders
- Built-in image enhancers and upscalers, including GFPGAN and realESRGAN
- Run additional upscaling models on CPU to save VRAM
- Textual inversion 🔥: info - requires enabling, see here, script works as usual without it enabled
- Advanced img2img editor with Mask and crop capabilities
- Mask painting 🖌️: Powerful tool for re-generating only specific parts of an image you want to change (currently Gradio only)
- More diffusion samplers 🔥🔥: A great collection of samplers to use, including:
k_euler(Default)k_lmsk_euler_ak_dpm_2k_dpm_2_ak_heunPLMSDDIM
- Loopback ➿: Automatically feed the last generated sample back into img2img
- Prompt Weighting 🏋️: Adjust the strength of different terms in your prompt
- Selectable GPU usage with
--gpu <id> - Memory Monitoring 🔥: Shows VRAM usage and generation time after outputting
- Word Seeds 🔥: Use words instead of seed numbers
- CFG: Classifier free guidance scale, a feature for fine-tuning your output
- Automatic Launcher: Activate conda and run Stable Diffusion with a single command
- Lighter on VRAM: 512x512 Text2Image & Image2Image tested working on 4GB
- Prompt validation: If your prompt is too long, you will get a warning in the text output field
- Copy-paste generation parameters: A text output provides generation parameters in an easy to copy-paste form for easy sharing.
- Correct seeds for batches: If you use a seed of 1000 to generate two batches of two images each, four generated images will have seeds:
1000, 1001, 1002, 1003. - Prompt matrix: Separate multiple prompts using the
|character, and the system will produce an image for every combination of them. - Loopback for Image2Image: A checkbox for img2img allowing to automatically feed output image as input for the next batch. Equivalent to saving output image, and replacing input image with it.
Stable Diffusion Web UI
A fully-integrated and easy way to work with Stable Diffusion right from a browser window.
Streamlit
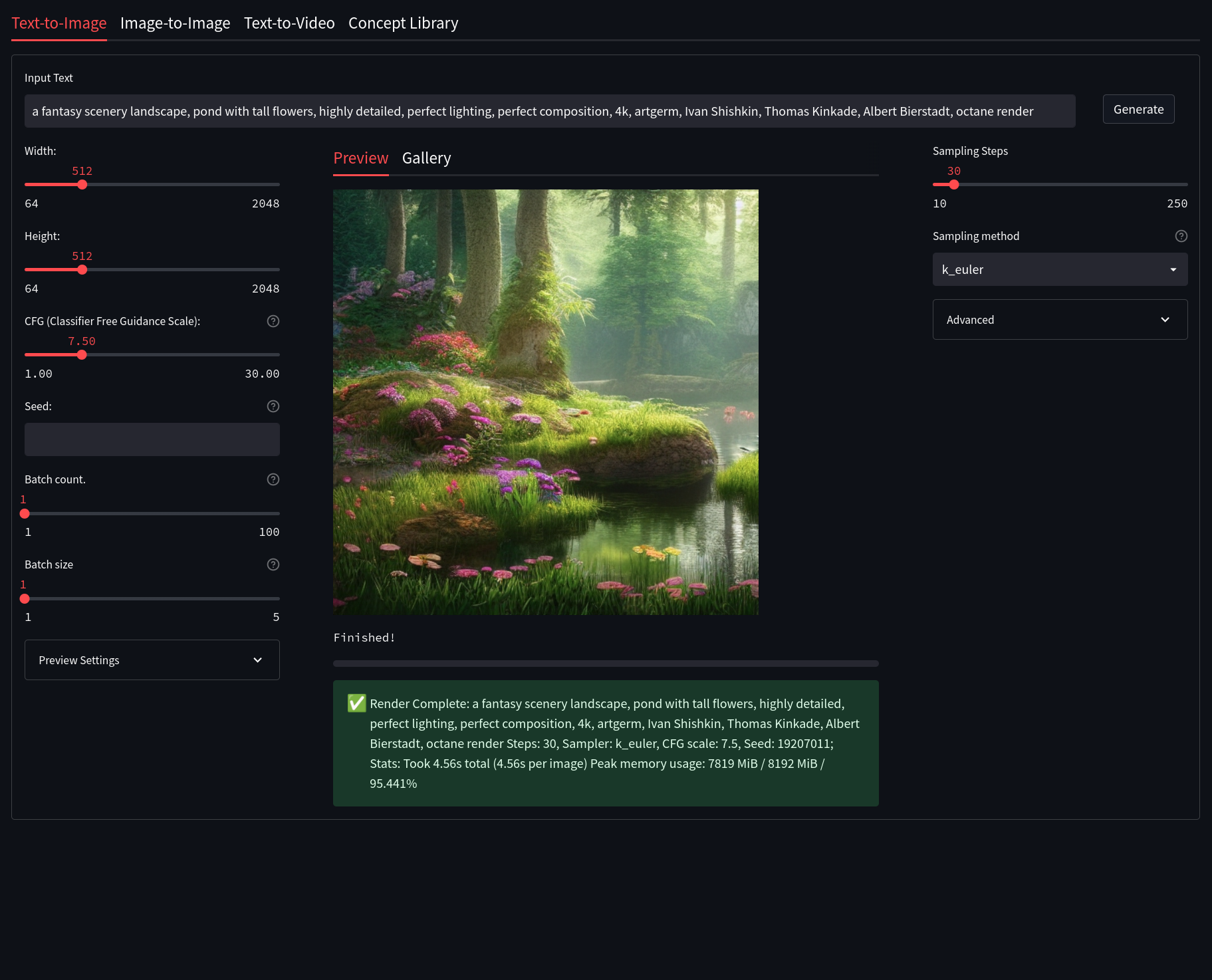
Features:
- Clean UI with an easy to use design, with support for widescreen displays.
- Dynamic live preview of your generations
- Easily customizable presets right from the WebUI (Coming Soon!)
- An integrated gallery to show the generations for a prompt or session (Coming soon!)
- Better optimization VRAM usage optimization, less errors for bigger generations.
- Text2Video - Generate video clips from text prompts right from the WEb UI (WIP)
- Concepts Library - Run custom embeddings others have made via textual inversion.
- Actively being developed with new features being added and planned - Stay Tuned!
- Streamlit is now the new primary UI for the project moving forward.
- Currently in active development and still missing some of the features present in the Gradio Interface.
Please see the Streamlit Documentation to learn more.
Gradio
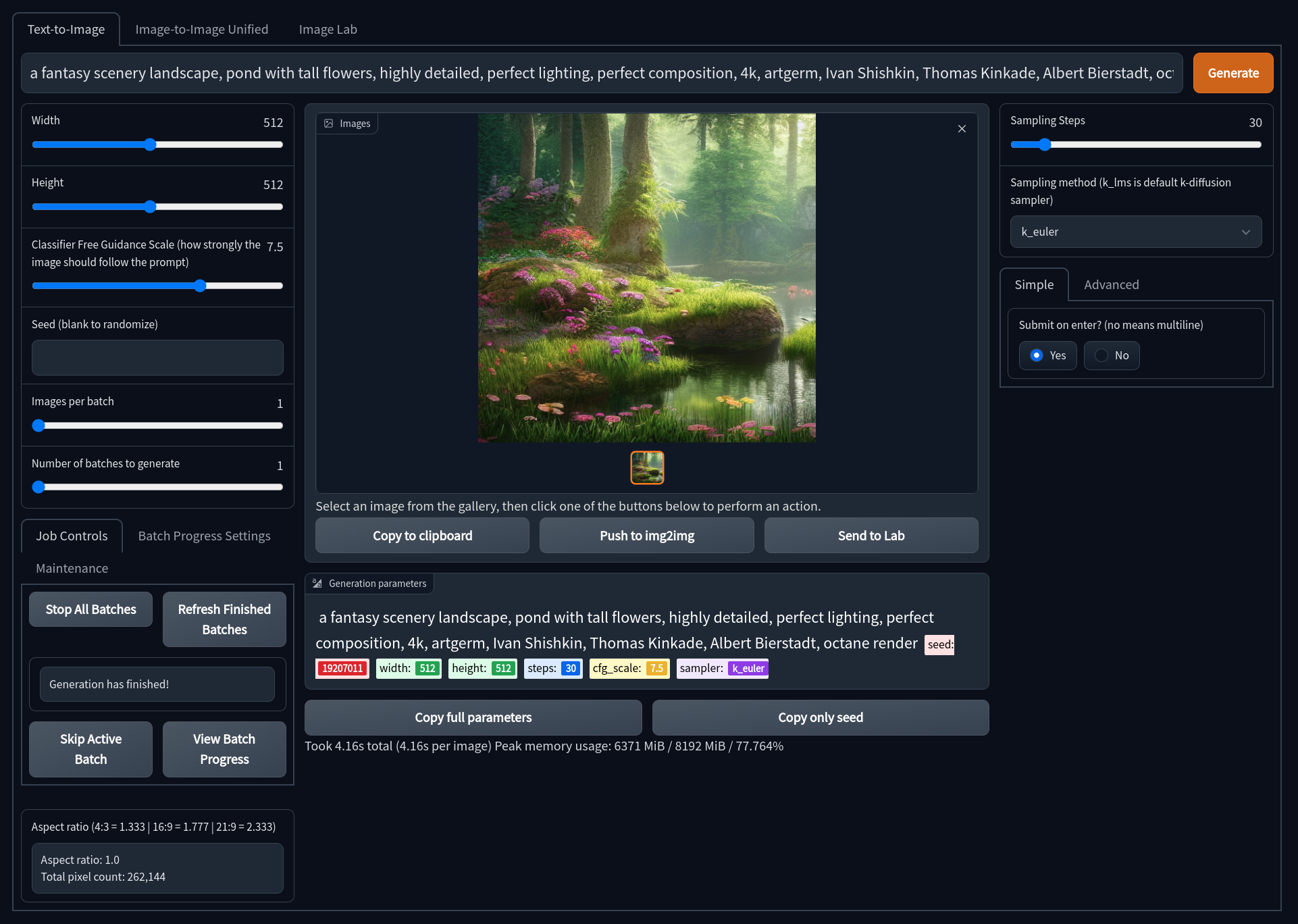
Features:
- Older UI design that is fully functional and feature complete.
- Has access to all upscaling models, including LSDR.
- Dynamic prompt entry automatically changes your generation settings based on
--paramsin a prompt. - Includes quick and easy ways to send generations to Image2Image or the Image Lab for upscaling.
- Note, the Gradio interface is no longer being actively developed and is only receiving bug fixes.
Please see the Gradio Documentation to learn more.
Image Upscalers
GFPGAN

Lets you improve faces in pictures using the GFPGAN model. There is a checkbox in every tab to use GFPGAN at 100%, and also a separate tab that just allows you to use GFPGAN on any picture, with a slider that controls how strong the effect is.
If you want to use GFPGAN to improve generated faces, you need to install it separately.
Download GFPGANv1.3.pth and put it
into the /stable-diffusion-webui/src/gfpgan/experiments/pretrained_models directory.
RealESRGAN

Lets you double the resolution of generated images. There is a checkbox in every tab to use RealESRGAN, and you can choose between the regular upscaler and the anime version. There is also a separate tab for using RealESRGAN on any picture.
Download RealESRGAN_x4plus.pth and RealESRGAN_x4plus_anime_6B.pth.
Put them into the stable-diffusion-webui/src/realesrgan/experiments/pretrained_models directory.
GoBig, LSDR, and GoLatent (Currently Gradio Only)
More powerful upscalers that uses a seperate Latent Diffusion model to more cleanly upscale images.
Download LDSR project.yaml and model last.cpkt. Rename last.ckpt to model.ckpt and place both under stable-diffusion-webui/src/latent-diffusion/experiments/pretrained_models/
Please see the Image Enhancers Documentation to learn more.
Original Information From The Stable Diffusion Repo
Stable Diffusion
Stable Diffusion was made possible thanks to a collaboration with Stability AI and Runway and builds upon our previous work:
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach*,
Andreas Blattmann*,
Dominik Lorenz\,
Patrick Esser,
Björn Ommer
CVPR ‘22 Oral
which is available on GitHub. PDF at arXiv. Please also visit our Project page.
Stable Diffusion is a latent text-to-image diffusion model. Thanks to a generous compute donation from Stability AI and support from LAION, we were able to train a Latent Diffusion Model on 512x512 images from a subset of the LAION-5B database. Similar to Google’s Imagen, this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM. See this section below and the model card.
Stable Diffusion v1
Stable Diffusion v1 refers to a specific configuration of the model architecture that uses a downsampling-factor 8 autoencoder with an 860M UNet and CLIP ViT-L/14 text encoder for the diffusion model. The model was pretrained on 256x256 images and then finetuned on 512x512 images.
*Note: Stable Diffusion v1 is a general text-to-image diffusion model and therefore mirrors biases and (mis-)conceptions that are present in its training data. Details on the training procedure and data, as well as the intended use of the model can be found in the corresponding model card.
Comments
-
Our codebase for the diffusion models builds heavily on OpenAI’s ADM codebase and https://github.com/lucidrains/denoising-diffusion-pytorch. Thanks for open-sourcing!
-
The implementation of the transformer encoder is from x-transformers by lucidrains.
BibTeX
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}