Windows Installation
Initial Setup
This is a windows guide. To install on Linux, see this page.
Pre requisites
Install Git & Miniconda :
- https://gitforwindows.org/ Download this, and accept all of the default settings it offers except for the default editor selection. Once it asks for what the default editor is, most people who are unfamiliar with this should just choose Notepad because everyone has Notepad on Windows.
-
Download Miniconda3: https://repo.anaconda.com/miniconda/Miniconda3-latest-Windows-x86_64.exe Get this installed so that you have access to the Miniconda3 Prompt Console.
-
Open Miniconda3 Prompt from your start menu after it has been installed
-
(Optional) Create a new text file in your root directory
/stable-diffusion-webui/custom-conda-path.txtthat contains the path to your relevant Miniconda3, for exampleC:\Users\<username>\miniconda3(replace<username>with your own username). This is required if you have more than 1 miniconda installation or are using custom installation location.
Cloning the repo
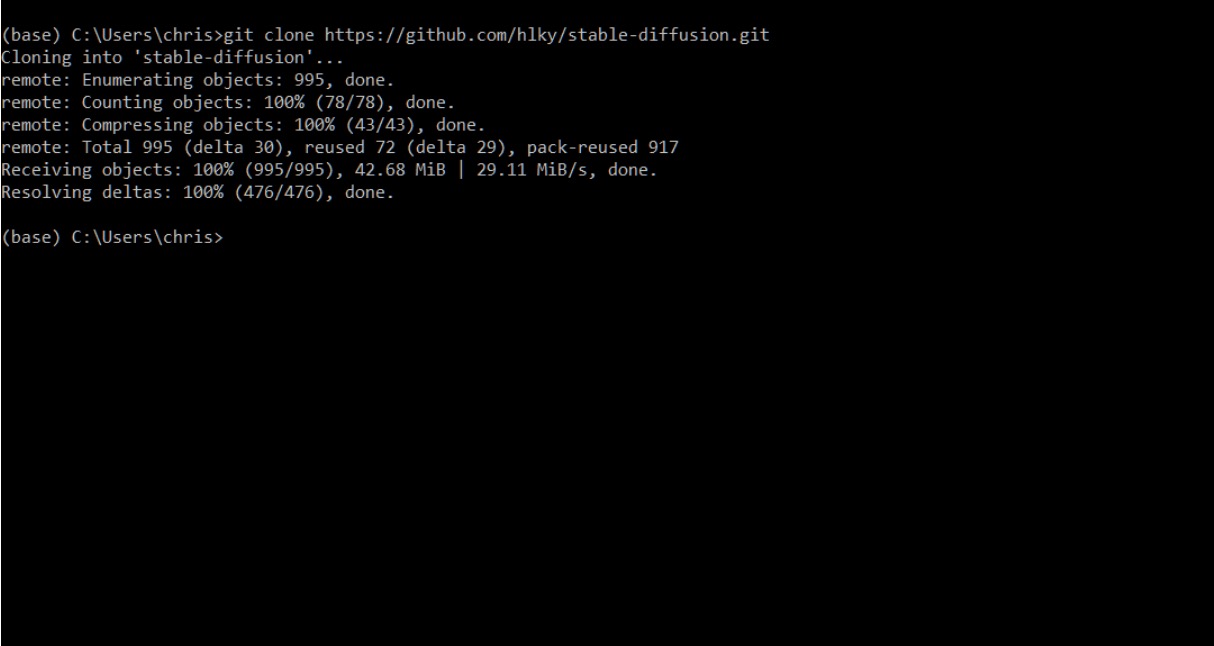
Type git clone https://github.com/sd-webui/stable-diffusion-webui.git into the prompt.
This will create the stable-diffusion-webui directory in your Windows user folder.
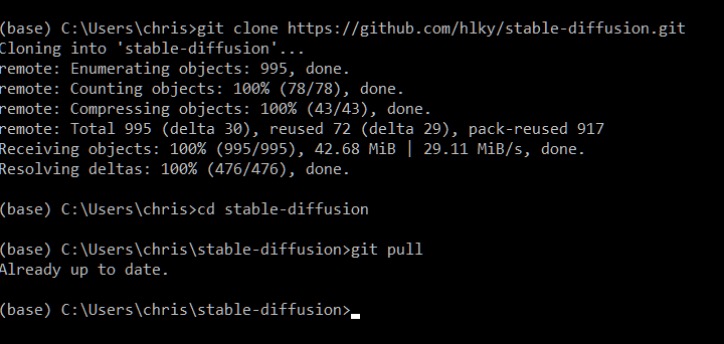
Once a repo has been cloned, updating it is as easy as typing git pull inside of Miniconda when in the repo’s topmost directory downloaded by the clone command. Below you can see I used the cd command to navigate into that folder.
-
Next you are going to want to create a Hugging Face account: https://huggingface.co/
-
After you have signed up, and are signed in go to this link and click on Authorize: https://huggingface.co/CompVis/stable-diffusion-v-1-4-original
-
After you have authorized your account, go to this link to download the model weights for version 1.4 of the model, future versions will be released in the same way, and updating them will be a similar process : https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt
-
Download the model into this directory:
C:\Users\<username>\stable-diffusion-webui\models\ldm\stable-diffusion-v1 -
Rename
sd-v1-4.ckpttomodel.ckptonce it is inside the stable-diffusion-v1 folder. -
Since we are already in our stable-diffusion-webui folder in Miniconda, our next step is to create the environment Stable Diffusion needs to work.
-
(Optional) If you already have an environment set up for an installation of Stable Diffusion named ldm open up the
environment.yamlfile in\stable-diffusion-webui\change the environment name inside of it fromldmtoldo
First run
webui.cmdat the root folder (\stable-diffusion-webui\) is your main script that you’ll always run. It has the functions to automatically do the followings:- Create conda env
- Install and update requirements
- Run the relauncher and webui.py script for gradio UI options
-
Run
webui.cmdby double clicking the file. - Wait for it to process, this could take some time. Eventually it’ll look like this:

-
You’ll receive warning messages on GFPGAN, RealESRGAN and LDSR but these are optionals and will be further explained below.
-
In the meantime, you can now go to your web browser and open the link to http://localhost:7860/.
-
Enter the text prompt required and click generate.
-
You should be able to see progress in your
webui.cmdwindow. The http://localhost:7860/ will be automatically updated to show the final image once progress reach 100% -
Images created with the web interface will be saved to
\stable-diffusion-webui\outputs\in their respective folders alongside.yamltext files with all of the details of your prompts for easy referencing later. Images will also be saved with their seed and numbered so that they can be cross referenced with their.yamlfiles easily.
Optional additional models
There are three more models that we need to download in order to get the most out of the functionality offered by sd-webui.
The models are placed inside
srcfolder. If you don’t havesrcfolder inside your root directory it means that you haven’t installed the dependencies for your environment yet. Follow this step before proceeding.
GFPGAN
- If you want to use GFPGAN to improve generated faces, you need to install it separately.
- Download GFPGANv1.3.pth and put it
into the
/stable-diffusion-webui/src/gfpgan/experiments/pretrained_modelsdirectory.
RealESRGAN
- Download RealESRGAN_x4plus.pth and RealESRGAN_x4plus_anime_6B.pth.
- Put them into the
stable-diffusion-webui/src/realesrgan/experiments/pretrained_modelsdirectory.
LDSR
- Detailed instructions here. Brief instruction as follows.
- Git clone Hafiidz/latent-diffusion into your
/stable-diffusion-webui/src/folder. - Run
/stable-diffusion-webui/src/latent-diffusion/download_model.batto automatically download and rename the models. - Wait until it is done and you can confirm by confirming two new files in
stable-diffusion-webui/src/latent-diffusion/experiments/pretrained_models/ - (Optional) If there are no files there, you can manually download LDSR project.yaml and model last.cpkt.
- Rename last.ckpt to model.ckpt and place both under
stable-diffusion-webui/src/latent-diffusion/experiments/pretrained_models/. - Refer to here for any issue.
Credits
Big thanks to Arkitecc#0339 from the Stable Diffusion discord for the original guide (support them here). Modified by Hafiidz with helps from sd-webui discord and team.